
In the wider perspective of the current trends in modern application operations, IT environments are changing with the go-to-cloud strategies and application modernisation initiatives. There are…
- fewer servers,
- more containerized workloads,
- more PaaS resources in use,
- more cloud-native and serverless resources,
- and potentially an adoption of IoT devices at scale.
When it comes to operation support, it is obvious that the traditional monitoring and event management approaches will not be sufficient.
Traditionally, monitoring could detect that, for example, a server goes down, some service or process has died, or some watched metric is out of the tolerance level. There is then a need to fix this issue by performing either a server or service restart.
Now, when utilising more cloud-native resources in the mix, there is a need to see more than “there is something down”. In cloud environments, things rarely go completely down, but even if everything is working fine and all is green, there could be an outage caused by something else.
For this something else, there is a need for a more sophisticated approach. For that, you need an advanced platform for monitoring, and that is where AIOps can be leveraged.
AIOps Platform: Key Characteristics
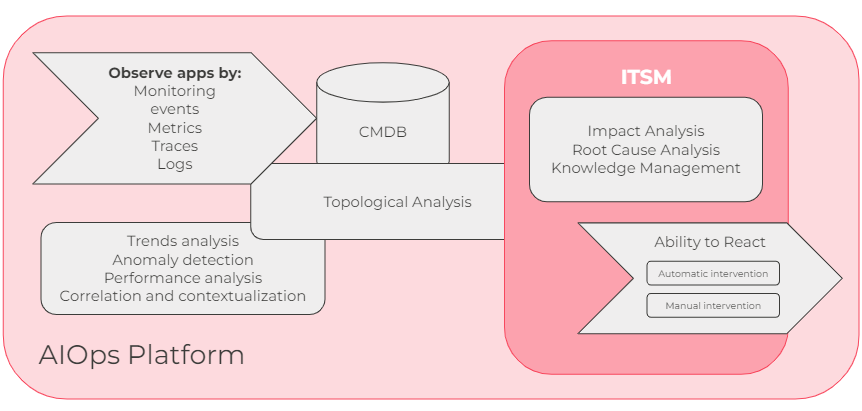
Let’s begin with data inputs from connected monitoring of all flavours, like infrastructural monitoring, metrics data, traces – meaning information about transactions and their latencies, along with log data.
From there, the next step is data analysis, where the tool can provide an outlook into trends with the ability to detect an anomaly. Also, we need to be able to identify the correlations between related and redundant data inputs. For this analysis, AI can be widely utilised.
Next, you need to be able to put the detected issue into the topological context based on the CI relationships and dependencies saved in the configuration database, in order to tell which services are affected.
An AIOps platform should be able to interact with the ITSM tickets, primarily with Incidents, Problems and Change Requests, where it gives context into what is the potential impact and the probable root cause. Moreover, the platform matches the issue with relevant and known solutions from the knowledge base.
The last – and probably the most important – step is the ability to react with the automatic and manual interventions with predefined remediation playbooks.
If the tool has all of these capabilities, then you can be sure, that it is an AIOps platform.
AIOps tools in the ServiceNow portfolio
Metric Intelligence
Metric Intelligence is a product that works with historical data and uses statistical modelling. It organises data into a time series and from that, it learns the behaviour of the infrastructure.
That is when Metric Intelligence is capable of making projections for the future. During the continuous data collection and evaluation, upper and lower bounds values are set, and trends or seasonalities are discovered automatically.
Boundaries are used to find statistical outliers – anomaly detection. These anomalies are then scored/classified. High anomaly scores for some CI metrics can indicate that a CI is at risk of causing a service outage, so alerts are automatically triggered.
Traditional Monitoring vs Anomaly detection and predictions
In Traditional monitoring, you need to create thresholds and rules manually. Over time, they are manually re-adjusted by learning from the past events that occurred in the system. As the complexity of the infrastructure increases, manual updates of these thresholds are get more and more complex and create room for mistakes, which means extra costs.
On the other hand, with Anomaly detection, you are focusing on behaviour in a time series, from which baselines are created. If there is something unusual or abnormal, an alert is triggered. Moreover, you can also predict future events by using statistical trends.
With event rules and the CMDB identification engine in ServiceNow, the collected data can be mapped to CIs and trigger alerts that are visible in the Operator Workspace, or you can see the whole processed data in the Insights Explorer.
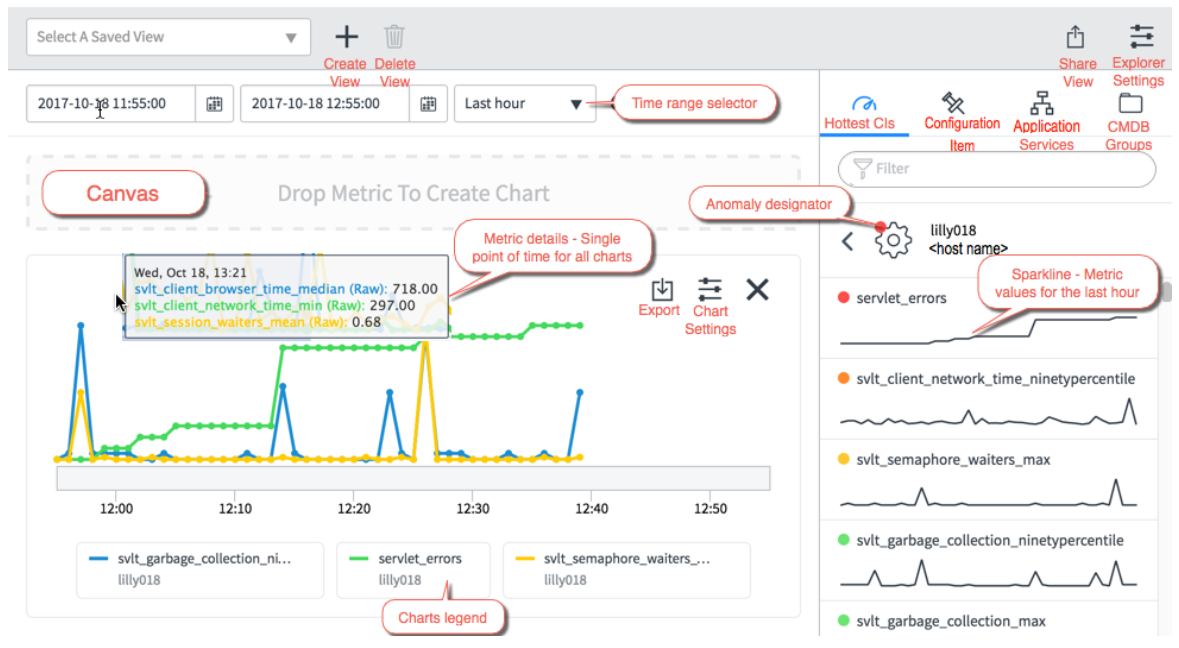
The Insights Explorer is a tool that shows the statistics, charts, and eventual anomalies across a timeline. It has a multi-layered view of all metrics for any CIs on a single page.
The navigation options are also very simple. On the top left, you can find the most important one:
- Hottest Configuration Items to quickly access CIs with the most anomalies.
- Configuration Items to create a separate custom list of any CIs from the CMDB, and then you can drag the corresponding metrics for these CIs to the canvas.
- Application Services to create a custom list of application services that let you drill down the connected CIs. You can then add metrics for these to the canvas as well.
- CMDB Groups to create a custom list of CMDB Groups that let you drill into the CIs of these groups. You can then add metrics for these CIs to the canvas.
Additionally, you can also select the monitored time range according to your needs.
Health Log Analytics
Health Log Analytics predicts IT issues before they affect your users. It is not just about log collection, but also log analytics.
How does the application help you solve problems faster? By collecting, understanding (parsing, normalising), and correlating machine-generated log data in real time.
With machine learning, it discovers deviation from normal behaviour, and when it happens, the system alerts you about possible issues. It also groups anomalies and applies further algorithms to help identify the root cause of the issue.
Health Log Analytics presents data in a logical, extracted form for operators to monitor at any time (in the already mentioned Operator Workspace). If necessary, it feeds meaningful alerts into the Event Management module.
HLA process steps:
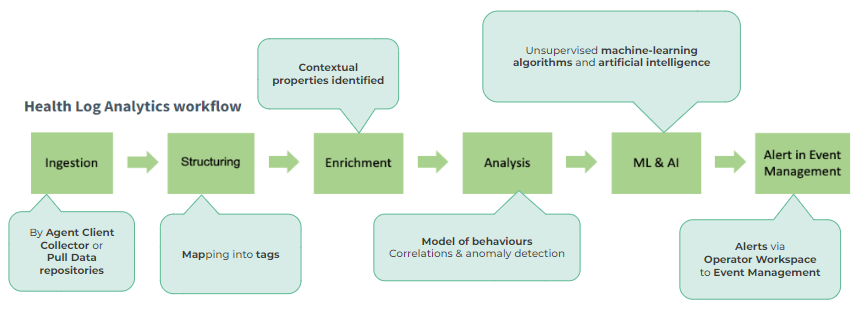
- Ingestion: data collection with Agent Client Collector, or importing data repositories with a pull mechanism.
- Structuring: This can be automatic or manual. The system extracts the essential information from the collected log samples, e.g. Message, Timestamp, Host, Severy, External-IDs and then, this information is automatically mapped to the appropriate tags.
- Enrichment: Here the system identifies keywords and contextual properties during data parsing, which is done by automatically running algorithms (Broker, Patternator, Metricator).
- Analysis: Anomaly detection, correlation & diagnosis. This is where HLA establishes behaviour models, or in other words: sets the expectations. Based on this, anomalous behaviour can be spotted (Algorithms – Metricator, Aggregator, Detective, Alerts creator, Correlator).
- Machine Learning (ML) and Artificial Intelligence (AI): AI runs in the background where advanced, unsupervised machine-learning algorithms are discovering patterns and unique behaviours. Then, ML sets dynamic thresholds based on the received data signature to identify possible issues. Here, it is also possible to send human feedback.
- Alert in Event Management: if the system detects a deviation from the typical pattern, it sends an alert to Event Management.
Site Reliability Operations
The goal of Site Reliability Operations (SRO) is to show service health for Site Reliability Engineer (SRE) teams. The product is divided into:
- Site Reliability Operations
- Site Reliability Metrics
That indicates that it works with the Service objectives and metrics, which are then presented to SRE teams to support their everyday operations.
Here, you can see a chart with setup steps and elements of the product:
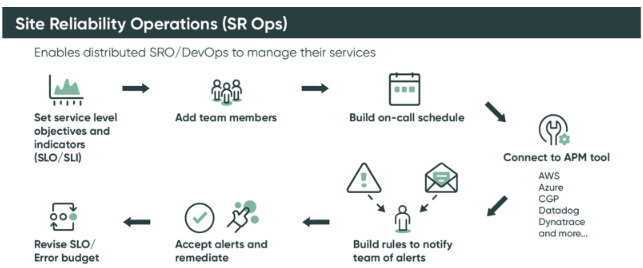
- Service-related components: creation and configuration of services…
- Add a service (name it and add a support team, create relations to other services, Metrics and properties e.g. version, environment)
- Integrate the APM tool of the service and create alert rules – there are predefined rules, but it is also possible to add new rules, conditions and actions to happen – e.g. notification;
- Create Service Level alerts – add actions to take e.g. “create incident”, “alert notification”.
- Operational components:
- Teams – SRO Team can be created through the ‘SRO Workspace’;
- Set up on-call schedules for the team;
- Add team members to the shifts;
- Add escalation policies (primary, secondary, catch-all), and rules on who receives notifications and when.
Site Reliability Metrics (SRM) defines 3 types of metrics:
- Service Level Indicator (SLI): used with APM connected conditions, measuring, e.g. the number of errors, machine restarts
- Service Level Objectives (SLO): where the limits and targets are set
- Error budget definition: here, you can add thresholds, set when to trigger actions to initiate alert or remediation activities, e.g. send notifications when the number of restarts endangers the SLO.
Site Reliability Operations Workspace can also be leveraged to respond to alerts. There is a specific page for the services and related records (alerts or incidents). With the remediation tasks, you can also initiate e.g. incident or change of tasks.
Next week, we will present one more Event Management tool that leverages the splendid opportunities of AI, and give our overview how all of these products can respond to the present-day needs of organisations.
Don’t hesitate to contact us to receive the most actual information regarding ServiceNow and its products. Feel free to reach out in case you are interested in a demo or professional services.

Certified ServiceNow Experts at your service
ServiceNow can empower your employees and clients with digitalized workflows, and Devoteam, as the #1 preferred Partner in the EMEA, is eager and ready to help make your digital transformation journey a success. Ready to see what we can bring to the table?

