
About the customer
FUGA is a world-leading b2b music distribution, marketing services and technology company that offers a flexible and customisable approach to meet the needs of content owners of all sizes. A division of Downtown Music, FUGA’s advanced music distribution technology, detailed analytics software, and royalty accounting suite give their customers the control they need to navigate the digital landscape as their needs evolve. With their client-centric attitude to business, FUGA helps music rights holders succeed by getting their content to more than 250 global music platforms, like YouTube Music and Spotify. Backed by a team of over 200 experts, they’re the go-to platform for independent labels, management agencies, and distributors. Its industry-leading agnostic platform allows their clients to choose the services that best suit their business plan, so they can seize opportunities and overcome challenges in the digital music market.
The problem: a missing note in the ML symphony
FUGA has several data scientists in its team, composing strong insights around their large amounts of data. They used to construct models orchestrated with a series of modular Python scripts and using a traditional machine learning cycle: data pre-processing, feature engineering, model training, evaluation phases and deployment. These processes cause a lot of operational overhead, leading to a high time-to-market and low development velocity. In their growing interest in advanced statistical models and machine learning, FUGA reached out to Devoteam G Cloud to accelerate their adoption of best practices and reduce their time-to-market.
The goal: accelerate, experiment, and empower
In the quest of fully leveraging their wealth of data for the good of artists and fans, FUGA wants to be able to seamlessly develop more ML models and bring them to production. This can be achieved with MLOps. In short, it is to machine learning what DevOps is to software development. It brings standardized, automated and resilient practices to increase release velocity for machine learning.
In addition to the improved velocity, FUGA was aiming to:
- Adopt a fully serverless architecture, enabling them to elastically scale to their requirements while decreasing costs in periods where they need fewer resources.
- Build robust ML pipelines, giving them a lot of flexibility for their experimentations, and ensuring the reproducibility of their results.
- Enforce the traceability of ML artefacts, providing visibility on the exact state and evolution of each individual step of ML processes.
- Take advantage of detailed monitoring, thanks to granular dashboards containing resources usage, evaluation metrics, and other important values.
By setting these goals, FUGA aimed to evolve their overall ML practices and, in doing so, secure a solid framework for advancing their goals. This transformation was rooted in their understanding that the real end goal encompassed not only the deployment of models but also a strategic foundation that would lead to greater confidence when deploying new ML models, faster release cycles, and substantial cost optimization.
To attain these goals, FUGA partnered with Devoteam G Cloud to adapt one of FUGA’s machine learning models to utilise solid MLOps principles, and then rely on Devoteam’s support to help FUGA towards the adoption of the new framework in their machine learning roadmap.

FUGA already benefits from using a variety of GCP services, including BigQuery. With the guidance and expertise from our Cloud Partner Devoteam, we can now leverage the latest in Google’s Artificial Intelligence service offerings and the strong data integrations across its cloud services to bring our data into a state-of-the-art Machine Learning environment that employs the best MLOps practices to date.
The solution: success with the Vertex AI Foundations from Devoteam
The model of this project tackles an important challenge for music publishers: predicting revenues on all available platforms. This ensures that music publishers can project their sales and plan accordingly. Underpinning this model with solid MLOps principles is of the utmost importance, as this model needs to be available continuously, make accurate predictions, and be easily maintainable by FUGA’s teams.
Leveraging Devoteam G Cloud’s Vertex AI Foundations
The Vertex AI Foundations, built by Devoteam G Cloud’s in-house experts, served as a framework, integrating the essential components required to establish reliable principles and operations within Vertex AI. Employing an infrastructure-as-code approach, this framework incorporates the necessary tooling to properly connect pipelines, components, packages, and containers to apply MLOps on Vertex AI.
Using the Vertex AI Foundations for this project brought, amongst others, the following benefits:
- Faster release cycles: instead of focusing on operational tasks (building artefacts, retraining models, manually experimenting with models parameters, …), machine learning engineers can focus on the core of their jobs: building better models that deliver more business value.
- Improved developer experience: thanks to the built-in integrations of the Vertex AI Foundations between Google Cloud services, code snippets and reusable services, adding new features to an ML project has never been easier.
- Scalability / traceability / reproducibility: the Vertex AI Foundations combines all Vertex AI and Google Cloud services necessary in your MLOps journey, bringing the required features to confidently deploy models in production.
Technical Solution Framework
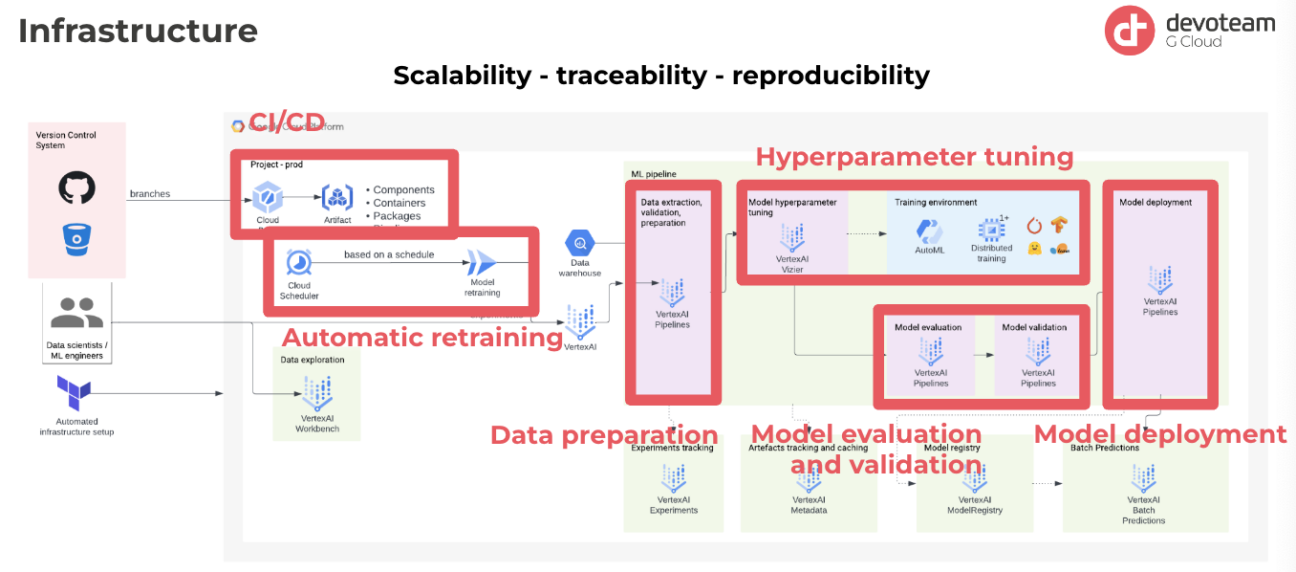
- Continuous Integration/Continuous Deployment (CI/CD): The solution includes a CI/CD pipeline that automates the creation of artefacts. This practice is essential because it allows for versioning of every artefact, providing complete visibility into the entire ML pipeline. This is beneficial because in the event of production issues, it is now possible to trace back to the model’s code, the specific pipeline used for training, and the exact components and packages used.
- Automated retraining for sustained performance: Another key feature is automatic retraining, which can be scheduled or triggered by evaluation metrics. If performance degradation is detected in production, the ML models can be automatically retrained. This practice aligns with the goal of ensuring that the model’s performance remains relevant over time.
- Enhancing Data Preparation: Although data preparation was performed by the client, Devoteam G Cloud optimized the process in terms of both parallelization and cost-effectiveness. This enhancement resulted in a significant increase in speed and efficiency. This was a critical improvement given that the ML pipeline included over 1,000 components.
- Hyperparameter Tuning with Vizier AI: Google’s Vizier AI is used to identify the optimal model parameters for peak performance. The tool recommends parameters based on conducted experiments and iteratively adapts suggestions to the specific problem being addressed, resulting in a fine-tuned and optimized model. After identifying the best model, thorough evaluation and validation ensure its capability against a dedicated test set.
- Efficient Evaluation and Automated Deployment: Models that pass performance benchmarks and validation criteria are enrolled in the model registry. The selected model is then deployed to Vertex AI through a fully automated process, making the transition from development to deployment easy.
The solution that Devoteam G Cloud provided us has exceeded all expectations, and they were already high. This will make a big difference in the direction of where FUGA is going as a company within the data space and has laid the foundation for new great steps ahead. We’ll be making sure to get the most out of your knowledge and expertise and hopefully, we can collaborate on more projects in the future. Really happy to report back to FUGA the amazing work you have done and how valuable it has been for us.
The methodology
The project started with the installation of the Vertex AI Foundations. Once the MLOps infrastructure was set up, Devoteam G Cloud’s engineers could start focusing on the development of the ML pipeline from FUGA’s existing code.
To enhance data preparation and model performance, refinements were made iteratively. Thorough documentation and insights were then shared with the FUGA team, facilitating their understanding of the Vertex AI Foundations and its usage.
Devoteam G Cloud will continue supporting FUGA in their adoption of the Vertex AI Foundations in their roadmap towards having more ML use cases. This collaborative approach ensures a gradual adoption and impactful outcomes over time for FUGA and their customers.
The results: efficiency, cost optimization and a foundation for their ML practices
The benefits of this project were tangible for FUGA: a surge in efficiency, cost optimization, and especially a robust foundation for their ML practices. FUGA now has the power to monitor each step of the pipeline, trace the origin of every artefact, and adapt models with ease. Not to mention, FUGA’s team was thrilled with the collaboration, and the solution will greatly assist them in the next stage of their machine learning journey.
A new standard of what we can do in the Data space with our company

Ready to speed up your AI & ML journey with the Vertex AI Foundations, just like Fuga?
Learn how Devoteam’s Vertex AI Foundations can accelerate your ML projects, ensuring quicker deployment, cost savings, and a strong foundation for success. Don’t hesitate – get in touch to start your journey and stay ahead using the latest machine learning technology.

